Statistics und Data Science
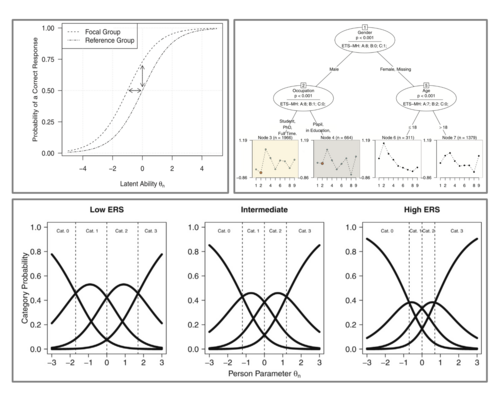
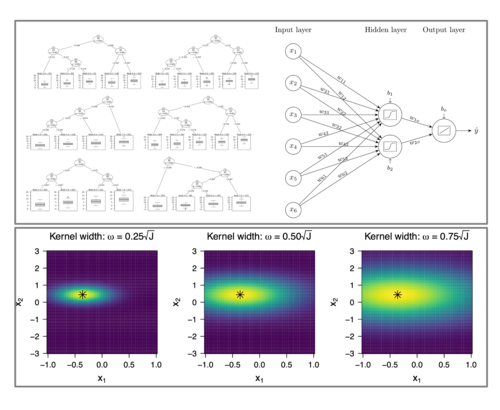
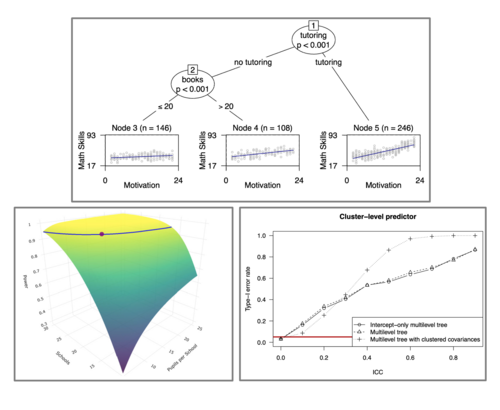
Wir betreiben Forschung in den folgenden drei Bereichen und ihren Schnittstellen: psychometrische Modellierung, Machine-Learning Methoden sowie Mehrebenen- und Längsschnittmodellierung. Einerseits untersuchen wir bestehende Verfahren, testen ihre Anwendbarkeit und zeigen Möglichkeiten und Schwierigkeiten für Analysen in der psychologischen Forschung auf. Andererseits entwickeln wir neue Verfahren und erweitern bestehende, um neue Möglichkeiten für die Datenanalyse und Hypothesengenerierung zu bieten. Unserer methodischer Ansatz besteht mehrheitlich aus Simulationsstudien, die in der Open-Source-Software R durchgeführt werden und Ilustrationen der neu- und weiterentwickelten Verfahren anhand empirischer Daten aus der Psychologie.
Neues SNSF Projekt
SNSF DATABASEAb Februar 2025 werden wir Machine-Learning Modelle untersuchen und erweitern, sodass sie auf hierarchisch strukturierte und longitudinale Daten in der Psychologie angewendet werden können. Dadurch wird es Forschenden in der Psychologie ermöglicht, in hierarchisch strukturierten Daten auch nonlineare Dynamiken psychologischer Prozesse explorativ zu untersuchen.